MLF Lecture 2 Perceptron Learning Algorithm
機器學習基石(Machine Learning Foundations)笔记第一弹
PLA 定义
用来解决线性可划分问题。 通过比较给定数据向量 X 与其权重向量 W 的加权和 \(\sum_{i=1}^d{w_ix_i}\) 与给定的阀值 therhold,决定是否同意某事(Y=1 or Y=-1) 即,\(h(x)=sign(\sum_{i=1}^d{w_{i}x_i} - threshold)\) 将上式中的(-threshold)看做 w0 ,附上(+1)的因子 x0 ,进一步变化:
\[\begin{aligned} h(x) &=sign \left( \sum_{i=1}^d{w_ix_i}+\underbrace{-threshold}_{w_0}\cdot(+1)\right) \\ &=sign(\sum_{i=0}^dw_ix_i) \\ &=sign(W^TX) \end{aligned}\]其中 WTX 为两个一维向量的内积。
PLA 过程
以二维向量为例,可以将\(h(x)=sign(w_0+w_1x_1+w_2x_2)\)括号内的部分看做一条关于 x 的直线。对每一个数据点\((x_1,x_2,\dots,x_n)\),不断修正当前直线的位置,直到所有点都满足 h(x)=yn(t)
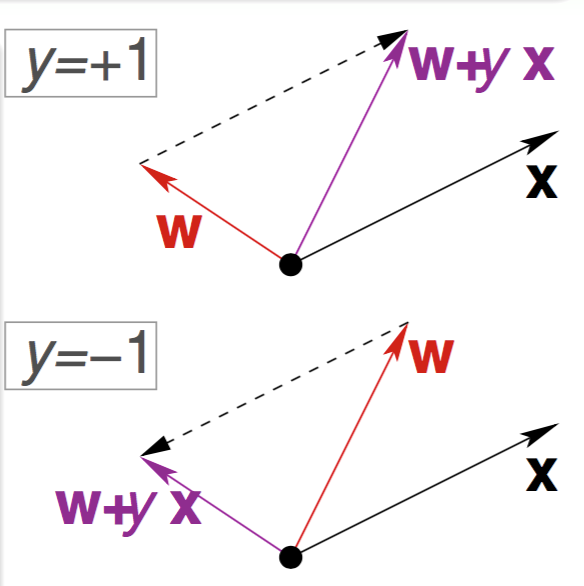
解释
- y = +1 时,\(\vec{W}\cdot\vec{X}<0\),需要减少\(\vec{W}\)与\(\vec{X}\)的夹角
- y = -1 时,\(\vec{W}\cdot\vec{X}>0\),需要增大\(\vec{W}\)与\(\vec{X}\)的夹角
算法
For \(t=0,1,\dots\)
find a \(\color{blue}{mistake}\) of \(\color{red}{W_t}\) called \(\color{blue}{\left(x_{n(t)},y_{n(t)}\right)}\)
\[\begin{aligned} sign\left(w_t^Tx_{n(t)}\right) \neq y_{n(t)} \end{aligned}\](try to) correct the mistake by
\[\begin{aligned} W_{t+1}\leftarrow W_t + y_{n(t)}x_{n(t)} \end{aligned}\]
... until \(\color{blue}{\text{no more mistakes}}\)
return \(\color{purple}{\text{last w (called }W_{PLA}\text{) as g}}\)
PLA 运行次数上限证明
仅当给定数据集线性可分时 PLA,PLA 可收敛。
线性可分(Linear Separability)
- \(\color{darkorange}{if}\) PLA
halts (i.e no more mistakes),
\(\color{darkorange}{\text{(necessary condition) }} D\) allows some w to make no mistake - call such \(D\color{darkorange}{\text{ linear separable}}\)
此时,可以假设存在我们需要的那个函数代表的向量\(W_f\)满足:
\[\begin{aligned} y_n(t)=sign(W_f^TX_n) \end{aligned}\]证明铺垫 1
\[\begin{aligned} y_{n(t)}W_f^TX_{(t)} \geq \mathop{min}\limits_{n}y_nW_f^TX_n > 0 \end{aligned}\]可以看出,当前向量 Wt 不断向理想向量 Wf 接近,因为两者的内积不断增大(但内积增大可能是由于向量长度的变化) \(\color{darkorange}{w_f^Tw_t\uparrow}\) by updating with any \(\color{purple}{\left(x_{n(t)},y_{n(t)}\right)}\)
\[\begin{aligned} w_t^Tw_{t+1} &= w_f^T\left(w_t + y_{n(t)}x_{n(t)}\right) \\ & \geq w_f^Tw_t + \color{blue}{\mathop{min}\limits_{n}y_nw_f^Tx_n} \\ & \color{red}{>} w_f^Tw_t + \color{red}{0} \end{aligned}\]证明铺垫 2
Wt 的模的增长速度受导致每个修正的错误点的限制 (\(\color{chocolate}{w_t \text{ changed only when mistake}}\))
\[\begin{aligned} \Leftrightarrow sign\left(\mathbf{w_t^Tx_{n(t)}}\righ t) \neq y_{n(t)} \Leftrightarrow \color{blue}{y_{n(t)}w_t^Tx_{n(t)} \leq 0} \end{aligned}\]
证明运行次数 T 的上限
先定义\(R^2=\mathop{max}\limits_{n}||x_n||^2\) \(\rho = \mathop{min}\limits_n y_n \dfrac{W_f^T}{||W_f||}X_n\)
由证明步骤 1 中结论:
\[\begin{aligned} W_f^TW_T &= W_f^T\left(W_{T-1} + y_{(T-1)}X_{(T-1)}\right) = W_f^T + y{(T-1)}W_f^TX_{(T-1)} \\ &\geq W_f^TW_{(T-1)} + miny W_f^TX \geq \dots \geq W_F^TW_0 + TminyW_F^TX = TminyW_f^TX \end{aligned}\]由证明步骤 2 中结论:
\[\begin{aligned} ||W_T||^2 \leq ||W_{T-1}|| + max \big||x|\big|^2 \leq \dots \leq ||W_0||^2 + T max\big||x|\big|^2 = Tmax\big||x|\big|^2 \end{aligned}\]用 R 和ρ 对以上两条不等式进行代换可得:
\[\begin{aligned} \dfrac{W_f^TW_T}{\left||W_f|\right|\left||W_T|\right|} \geq \sqrt T \dfrac\rho R \end{aligned}\]再由两个单位向量的内积 < 1,得到
\[\begin{aligned} T \leq \frac {R^2} {\rho^2} \end{aligned}\]算法收敛性得证
Pocket Algorithm
对 PLA 稍加改造:遍历结束时返回当前最优 Wt
用来应对无法确定 PLA 上界的问题。但由于每次更新 Wt 都要检查 Wt+1和 Wt 对所有点的正确数,所以相对 PLA 花费额外时间。
